


这是 Google 最近一篇论文 Nested Learning: The Illusion of Deep Learning Architectures 的翻译,优先阅读并尊重原文
这个文章现在具有较高的热度,可以看一看,模型自我迭代这个问题还是很有研究意义的
传统 Transformer 的核心局限是依赖静态权重来进行下一个 Token 的预测,导致难以适应快速变化的业务需求
然而,Nested Learning 的目标是引入一个多时间尺度的嵌套结构,使模型的部分组件能够快速更新与学习,从而在保持核心能力稳定的同时,实现实时的适应性与连续学习。
Nested Learning 是尝试让大模型学会学习,持续学习,使部分能力在推理时能够动态适应,而不是像传统 Transformer 那样完全依赖静态权重
Nested Learning: The Illusion of Deep Learning Architectures
Nested Learning:深度学习架构的幻觉
作者 Ali Behrouz, Meisam Razaviyayn, Peiling Zhong, Vahab Mirrokni Google Research, USA
摘要 (Abstract)
在过去的几十年里,开发更强大的神经架构(neural architectures)并同时设计能够有效训练它们的优化算法(optimization algorithms),一直是提升机器学习模型能力的研究核心。尽管最近取得了进展,特别是在开发大型语言模型(Language Models, LMs)方面,但在这些模型如何能够持续学习/记忆(continually learn/memorize)、自我提升(self-improved)以及寻找“有效解”方面,仍存在根本性的挑战和未解之答。在本文中,我们提出了一种新的学习范式,称为 Nested Learning (NL,嵌套学习)。NL 将模型连贯地表示为一组嵌套的、多层级的和/或并行的优化问题,其中每一个问题都有其自己的“context flow(上下文流)”。
NL 揭示了现有的深度学习方法是通过压缩其自身的 context flow 来从数据中学习的,并解释了 in-context learning(上下文内学习)是如何在大型模型中涌现的。NL 提出了一条路径(深度学习的一个新维度),用于设计具有更多“levels(层级)”的更具表达力的学习算法,从而产生更高阶的 in-context learning 能力。除了其在神经科学上的合理性和数学上的白盒(white-box)特性外,我们通过提出三个核心贡献来通过 NL 倡导其重要性:
- Deep Optimizers(深度优化器):基于 NL,我们展示了著名的基于梯度的优化器(例如 Adam、带 Momentum 的 SGD 等)实际上是 associative memory(联想记忆)模块,其目的是通过梯度下降来压缩梯度。基于这一洞察,我们提出了一组具有深度记忆(deep memory)和/或更强大更学习规则的更具表达力的优化器;
- Self-Modifying Titans(自我修正的 Titans):利用 NL 对学习算法的见解,我们提出了一种新颖的序列模型,该模型通过学习其自身的更新算法来学习如何修正自身;
- Continuum Memory System(连续统记忆系统):我们提出了一种新的记忆系统公式,推广了传统的“长期/短期记忆(long-term/short-term memory)”观点。
结合我们的自我修正序列模型与连续统记忆系统,我们提出了一个名为 HOPE 的学习模块,在语言建模、持续学习(continual learning)和长上下文推理任务中展示了充满前景的结果。
1. 引言 (Introduction)
本版本的论文为了符合 NeurIPS 最终版的页数限制进行了大量精简,一些材料、实验、讨论和方法被移至附录,这可能会导致某些部分难以理解或造成不连贯。为避免这种情况,请阅读我们的 arXiv 版本 [1](将于 11 月 13 日发布)。
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
 在过去的几十年里,AI 研究一直专注于设计从数据 [2–5] 或经验 [6–8] 中学习的机器学习算法;通常通过基于梯度的方法优化参数 上的目标函数 。虽然传统的机器学习技术需要仔细的工程设计和领域专业知识来设计特征提取器,限制了它们直接处理和从自然数据中学习的能力 [9],但深度表示学习(deep representation learning)提供了一种全自动的替代方案,可以发现任务所需的表示。此后,深度学习已成为大规模计算模型不可分割的一部分,在化学和生物学 [10]、游戏 [11, 12]、计算机视觉 [13, 14] 以及多模态和自然语言理解 [15–17] 方面取得了开创性的成功。
在过去的几十年里,AI 研究一直专注于设计从数据 [2–5] 或经验 [6–8] 中学习的机器学习算法;通常通过基于梯度的方法优化参数 上的目标函数 。虽然传统的机器学习技术需要仔细的工程设计和领域专业知识来设计特征提取器,限制了它们直接处理和从自然数据中学习的能力 [9],但深度表示学习(deep representation learning)提供了一种全自动的替代方案,可以发现任务所需的表示。此后,深度学习已成为大规模计算模型不可分割的一部分,在化学和生物学 [10]、游戏 [11, 12]、计算机视觉 [13, 14] 以及多模态和自然语言理解 [15–17] 方面取得了开创性的成功。
像深度学习模型那样堆叠多个层(stacking multiple layers),为模型提供了更大的容量、更强的复杂特征表达能力以及更多的内部计算(例如 #FLOPS)[18–20],所有这些对于需要在先前固定的集合上进行分布内预测的静态任务来说都是关键且理想的特性。然而,这种深度设计并非解决所有挑战的通用方案,并且在多个方面无法帮助提升模型的表达能力,例如:(i) 深度模型的计算深度(computational depth)可能不会随着层数的增加而改变 [21, 22],这使得它们在实现复杂算法的能力上相比传统的浅层方法 [23] 并没有本质变化;(ii) 某些类别的参数容量可能随着模型深度/宽度的增加仅表现出边际改善 [24];(iii) 训练过程可能会收敛到次优解,主要是由于优化器或其超参数的次优选择;以及 (iv) 模型快速适应新任务、持续学习和/或泛化到分布外数据的能力可能不会随着堆叠更多层而改变,需要更仔细的设计。
克服上述挑战并增强深度学习模型能力的核心努力集中在:(1) 开发更具表达力的参数类别(即 neural architectures,神经架构)[13, 25–28];(2) 引入能更好地对任务建模的目标函数 [29–32];(3) 设计更高效/有效的优化算法以寻找更好的解或具有更强的抗遗忘能力 [33–36];以及 (4) 在做出“正确”的架构、目标和优化算法选择时,通过扩大模型规模来增强其表达能力 [24, 37, 38]。总的来说,这些进步和关于深度模型扩展模式(scaling patterns)的新发现奠定了构建大型语言模型(LLMs)的基础。
LLM 的发展标志着深度学习研究的一个关键里程碑:从特定任务模型向更通用的系统转变,这种转变是扩展“正确”架构的结果 [38, 39],带来了各种涌现能力(emergent capabilities)。尽管它们在各种任务中取得了成功并展现了卓越的能力 [15, 40, 41],但 LLM 在初始部署阶段之后基本上是静态的,这意味着它们成功执行了在预训练或后训练期间学到的任务,但无法在其直接上下文之外持续获取新能力。LLM 唯一可适应的组件是其 in-context learning(上下文内学习) 能力——这是 LLM 的一种(已知为涌现的)特性,使其能够快速适应上下文并执行零样本或少样本任务 [38]。除了 in-context learning 之外,最近为克服 LLM 静态性质所做的努力要么计算成本高昂,要么需要外部组件,缺乏泛化能力,和/或可能遭受灾难性遗忘(catastrophic forgetting)[42–44],这导致研究人员质疑是否有必要重新审视机器学习模型的设计方式,以及是否需要超越层堆叠的新学习范式来释放 LLM 在持续设置中的能力。
现有模型仅体验即时当下(Current Models only Experience the Immediate Present)。 为了类比并更好地说明 LLM 的静态性质,我们使用**顺行性遗忘症(anterograde amnesia)**的例子——一种神经系统疾病,患者在发病后无法形成新的长期记忆,而现有的记忆保持完好 [45]。这种情况将患者的知识和经历限制在当下和发病前长期的短暂窗口内——这导致患者不断地体验当下,仿佛一切总是新的。当前 LLM 的记忆处理系统遭受类似的模式。它们的知识仅限于适合其 context window(上下文窗口)的即时上下文,或者存储在 MLP 层中的知识,这些知识属于遥远的过去,即“预训练结束(end of pre-training)”之前。这一类比促使我们从神经生理学文献以及大脑如何巩固其短期记忆中汲取灵感:
1.1 人类大脑视角与神经生理学动机
当涉及到持续学习(即有效的上下文管理)时,人类大脑非常高效且有效,这通常归因于神经可塑性(neuroplasticity)——大脑响应新体验、记忆、学习甚至损伤而改变自身能力的非凡能力 [46, 47]。最近的研究支持长期记忆的形成至少涉及两个不同但互补的巩固过程 [48–50]:(1) 一个快速的“在线”巩固(online consolidation,也称为 synaptic consolidation,突触巩固)阶段,在学习后立即或不久发生,甚至在清醒时也是如此。这是新的且最初脆弱的记忆痕迹被稳定下来并开始从短期存储转移到长期存储的时候;(2) 一个“离线”巩固(offline consolidation,也称为 systems consolidation,系统巩固)过程,重复重放最近编码的模式——在海马体的 sharp-wave ripples (SWRs,尖波涟漪) 期间,与皮层睡眠纺锤波和慢振荡相协调——加强并重组记忆,并支持转移到皮层位点 [51–53]。
回到顺行性遗忘症的类比,证据表明这种情况会影响两个阶段,尤其是在线巩固阶段,主要是因为海马体是编码新陈述性记忆的门户,因此其损伤意味着新信息永远不会存储在长期记忆中。如上所述,LLM 的设计,更具体地说是基于 Transformer 的骨干网络,在预训练阶段之后遭受类似的情况。也就是说,上下文中提供的信息永远不会影响长期记忆参数(例如,前馈层),因此模型无法获取新知识或技能,除非信息仍然存储在短期记忆(例如,注意力机制)中。为此,虽然第二阶段对于记忆的巩固同样甚至更为关键,且其缺失可能会破坏该过程并导致记忆丧失 [54, 55],但在本工作中,我们专注于第一阶段:作为在线过程的记忆巩固。我们在附录 A 中提供了关于人类大脑视角及其与 NL 联系的更多讨论。
符号说明。我们设 为输入, 表示在时刻 的记忆/模型 的状态, 为键(keys), 为值(values), 为查询(query)矩阵。我们使用带有下标 的粗体小写字母来指代对应于输入 的向量(即 和 )。我们进一步将任何实体 的分布称为 。在整篇论文中,我们使用简单的具有 层和残差连接的 MLP 作为记忆模块 的架构。当需要时,我们用 参数化记忆模块,这至少包括 MLP 中线性层的参数。我们使用带括号的上标来指代嵌套学习不同 levels(不同更新频率)中的参数:即 。
2. 嵌套学习 (Nested Learning)
本节讨论 Nested Learning (NL) 的动机、形式定义和一般的高层含义。我们从 associative memory(联想记忆)的公式开始,然后通过循序渐进的例子,建立架构分解(architecture decomposition)的直觉,及其与将神经网络建模为优化问题集成系统的联系。我们旨在首先展示深度学习中的现有方法和概念如何归入 NL 范式,然后提出超越传统方法的新公式,并/或提供有关如何改进现有算法和设计的见解。
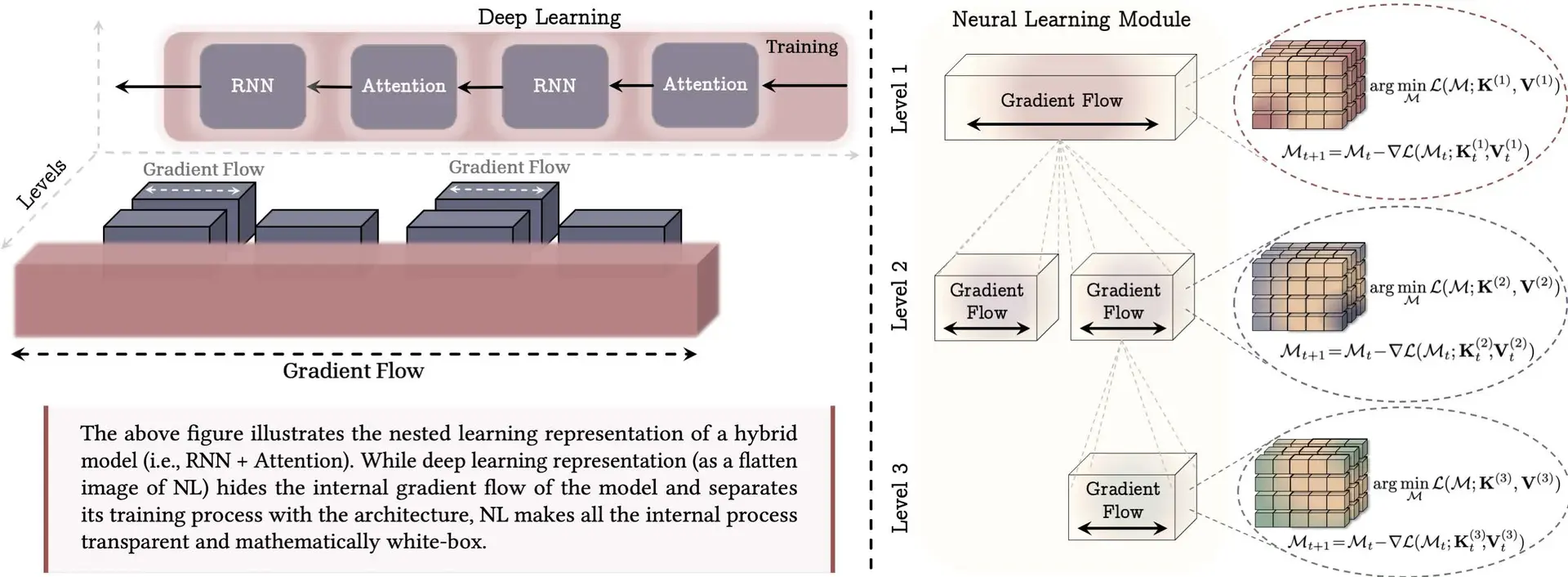 图 2:嵌套学习范式(Nested Learning Paradigm)
图 2:嵌套学习范式(Nested Learning Paradigm)
将机器学习模型及其训练过程表示为一系列嵌套的优化问题。(左)一个混合架构(Hybrid architecture)的示例。从深度学习的角度来看,作为嵌套学习(NL)“展平”图像的形式,并不能提供关于各模块计算深度的洞察,而嵌套学习能够透明地表示所有内部梯度流。(右)一个神经学习模块(Neural Learning Module):一种能够学习如何压缩自身上下文流的计算模型。例如,第一级对应模型最外层的训练循环,通常被称为“预训练(pre-training)”步骤。
2.1 联想记忆 (Associative Memory)
联想记忆——形成和检索事件之间联系的能力——是一种基本的心理过程,也是人类学习不可分割的组成部分 [56]。在文献中,记忆(memorization)和学习(learning)的概念经常互换使用;然而,在神经心理学文献中,这两者有明显的区别。更具体地,遵循神经心理学文献 [57],我们基于以下记忆和学习的定义构建我们的术语:
学习 vs. 记忆 (Learning vs. Memorization):
记忆 (Memory) 是由输入引起的神经更新,而 学习 (Learning) 是获取有效和有用记忆的过程。
在这项工作中,我们的目标是首先展示计算序列模型的所有元素,包括优化器和神经网络,都是压缩其自身 context flow(上下文流) 的 associative memory systems(联想记忆系统)。广义上讲,联想记忆是一种将一组键(keys)映射到一组值(values)的算子。我们遵循 Behrouz 等人 [58] 对联想记忆的一般定义:
定义 1(联想记忆 Associative Memory)。 给定一组键 和值 ,联想记忆是一个算子 ,它映射两组键 和值 。为了从数据中学习这种映射,目标函数 衡量映射的质量, 可以定义为:
虽然算子本身是一种记忆,映射行为是一种记忆化过程(即,记忆上下文中事件的连接),但基于数据获取这种有效算子是一个学习过程。值得注意的是,在这里,键和值可以是记忆旨在映射它们的任意事件,不仅限于 token。本节稍后我们将讨论,给定一个 context flow,键和值可以是 token、梯度、子序列等。此外,虽然联想记忆一词在神经科学和神经心理学文献中更为常见,但上述公式也与数据压缩和低维表示密切相关。也就是说,人们可以将方程 1 中的优化过程解释为网络 的训练过程,其目的是将映射压缩到其参数中,从而在低维空间中表示它们。
在序列建模中,键和值是输入 token(例如,token 化的文本),目标函数的选择和求解方程 1 的优化过程可能导致不同的序列建模架构(见 [59] 和 [58]),如全局/局部 softmax attention [27],或其他现代循环模型 [28, 60, 61]。这种简单的序列模型公式让我们更好地理解其内部过程,并提供了一种工具,可以根据其目标和优化过程简单地比较它们的建模能力。接下来,我们使用循序渐进的例子,讨论这种公式如何应用于神经架构的所有组件(包括其预训练中的优化过程),实际上,模型是如何作为一个多层级、嵌套和/或并行记忆的集成系统,其中每一个都有自己的 context flow。
MLP 训练的一个简单例子。 我们从一个简单的例子开始,在这个例子中,我们旨在为任务 训练一个单层 MLP(由 参数化),数据集为 ,通过梯度下降优化目标 。在这种情况下,训练过程等同于以下优化问题:
通过梯度下降对其进行优化会导致权重更新规则等同于:
其中 是模型对输入 的输出。给定此公式,我们可以令 并将反向传播过程重新表述为优化问题的解,即寻找一个最佳联想记忆,将输入数据点 映射到其对应的 。也就是说,我们令 参数化记忆,并使用点积相似度来衡量 在 和 之间映射的质量:
在上述公式中, 可以解释为表示空间中的局部惊奇信号 (local surprise signal in representation space),它量化了当前输出与目标 强制的结构之间的不匹配。因此,该公式将模型的训练阶段转化为获取有效记忆的过程,该记忆将数据样本映射到其表示空间中的局部惊奇信号(LSS)——定义为当前输出与目标 强制的结构之间的不匹配。相应地,在这个例子中,我们的模型在数据样本上有一个单一的梯度流 (single gradient flow),它仅在数据集 上活跃,之后对任何其他数据样本(即推理或测试时间)将被冻结。
接下来,在上述例子中,我们将梯度下降算法替换为其增强的基于动量(momentum-based)的变体,产生的更新规则为:
在方程 8 中,给定方程 7 的前一状态(在时刻 ), 或类似的 的值独立于方程 8 中的递归,因此可以预先计算。为此,我们令 ,于是方程 8 可以重新表述为:
其中方程 10 中的优化问题等同于一步自适应学习率为 的梯度下降。给定这些公式,我们可以将动量项解释为:(1) 一个无键(key-less)联想记忆,将其压缩到参数中;或 (2) 一个联想记忆,学习如何将数据点映射到其对应的 LSS 值。有趣的是,这个公式揭示了带动量的梯度下降实际上是一个两层(two-level)优化过程,其中记忆通过简单的梯度下降算法进行优化。此过程与 Fast Weight Programs (FWPs) [62] 密切相关,其中权重更新过程(即方程 9)是慢速网络(slow network),其动量权重由快速网络(fast network,即方程 10)生成。
总结上述例子,我们观察到单层 MLP 的训练过程: (1) 使用梯度下降是一个 1-level 联想记忆,学习如何将数据点映射到其对应的 LSS 值; (2) 使用带动量的梯度下降是一个 2-level 联想记忆(或优化过程),内层学习将梯度值存储到其参数中,然后外层用内层记忆的值更新慢速权重(即 )。虽然这些是架构和优化器算法方面最简单的例子,但人们可能会问是否可以在更复杂的设置中得出类似的结论。
架构分解的一个例子 (An Example of Architectural Decomposition)。 在下一个例子中,我们将 MLP 模块替换为 linear attention(线性注意力)[60]。也就是说,我们旨在为任务 在序列 上训练一个单层线性注意力,通过梯度下降优化目标 。回顾未归一化的线性注意力公式:
正如早期研究 [58, 59] 所讨论的,方程 13 中的递归可以重新表述为一个矩阵值联想记忆 的优化过程,其中它旨在将键和值的映射压缩到其参数中。更详细地说,在定义 1 中,如果我们令 并旨在用梯度下降优化记忆,记忆更新规则为:(注意 且我们设学习率 )
这等同于方程 13 中未归一化线性注意力的更新规则。此外,请注意,我们在第一个例子中观察到,用梯度下降训练线性层是一个联想记忆的 1 层优化问题(见方程 3),因此投影层(即 和 )的一般训练/更新过程本身就是一个联想记忆的优化过程。相应地,这种设置,即用梯度下降训练线性注意力,可以被视为一个 2-level 优化过程,其中外循环(也称为训练过程)用梯度下降优化投影层,而内循环用梯度下降优化 的内部记忆。
请注意,如上所述,这里我们有两个联想记忆,每一个都有自己的优化过程和梯度流。也就是说,在 和 的外层参数优化中,没有关于参数 的梯度,因此没有反向传播穿过它。类似地,在内层中,没有反向传播穿过投影层,它们被认为是冻结的。此外,值得注意的是,在这个例子中,上述公式也与线性注意力的 FWPs 视角密切相关 [63],其中投影被认为是慢速权重,而方程 13 中的记忆更新是快速权重更新规则。
更多层级的架构分解。 在上述两个例子中,我们讨论了简单的情况,它们可以被转化为 2-level 优化过程,这也与它们的 FWPs 解释一致。然而,在实践中,我们需要使用更强大的优化算法来训练模型,和/或为记忆使用更强大的循环更新规则。作为一个简单的例子,假设我们使用带动量的梯度下降来训练线性注意力模型。在上面的例子中,我们展示了线性注意力组件如何分解为两个嵌套的优化问题。类似地,这里模型可以表示为一个 2-level 优化问题,其中 (1) 内层使用梯度下降优化记忆以压缩上下文(见方程 15),以及 (2) 外层使用带动量的梯度下降优化投影层。有趣的是,从第一个例子我们知道,“带动量的梯度下降”算法本身实际上是一个 2-level 优化问题,其中动量项本身是一个将过去的梯度压缩到其参数中的联想记忆。
2.2 嵌套优化问题 (Nested Optimization Problems)
在上一节中,我们提供了例子来演示如何将机器学习模型分解为一组嵌套或多级优化问题。接下来,我们旨在首先提出嵌套学习问题的形式化公式,然后定义 Neural Learning Module(神经学习模块)——一个从数据中学习的集成计算系统。
正如我们在上一节中观察到的,虽然我们将模型分解为一组优化过程,但仍然不清楚我们是否可以在这些问题上定义一个层级(或顺序),并以这种格式唯一地表示模型。受大脑波层级结构的启发,该结构表明每个部分的信息处理频率率(在第 1 节中讨论),我们使用每个优化问题的更新率在多个 levels 上对组件进行排序。为此,我们将一个数据点上的一个更新步骤作为时间单位,并定义每个组件的更新频率率为:
定义 2(更新频率 Update Frequency)。 对于 的任何组件,它可以是参数组件(例如,可学习的权重或带动量的梯度下降中的动量项)或非参数组件(例如,注意力块),我们将其频率(记为 )定义为单位时间内的更新次数。
给定上述更新频率,我们可以基于算子 对机器学习算法的组件进行排序。我们令 比 快并记作 如果:(1) ,或者 (2) 但 在时刻 的状态计算需要 在时刻 的状态计算。在这个定义中,当 且 时,我们令 ,这表示 和 具有相同的频率更新,但它们的计算相互独立(稍后我们在 AdamW 优化器中提供这种情况的例子)。基于上述算子,我们将组件排序为一个有序的“levels”集合,其中 (1) 同一 level 的组件具有相同的频率更新,(2) level 越高,其频率越低。值得注意的是,基于上述定义,每个组件都有其自己的优化问题和上下文。虽然我们用基于梯度的优化器优化组件的内部目标,但上述陈述等同于模型中每个组件都有独占的梯度流。但在一般情况下,人们可以使用非参数解(正如我们稍后讨论的注意力)。
神经学习模块 (Neural Learning Module)。 给定上述嵌套学习问题的定义,我们将神经学习模块定义为机器学习模型的一种新表示方式,它将模型显示为相互连接的组件系统,每个组件都有其自己的梯度流。请注意,与深度学习正交,嵌套学习允许我们定义具有更多 levels 的神经学习模型,从而产生更具表达力的架构。
Nested learning(嵌套学习) 允许由多个(多层)levels 组成的计算模型从不同抽象水平和时间尺度的数据中学习和处理数据。
接下来,我们从嵌套学习的角度研究优化器和著名的深度学习架构,并提供 NL 如何帮助增强这些组件的例子。
2.3 优化器作为学习模块 (Optimizers as Learning Modules)
在本节中,我们首先理解著名的优化器及其变体如何成为嵌套学习的特殊实例。回顾带动量的梯度下降方法,
其中矩阵(或向量) 是状态 的动量, 和 分别是自适应学习率和动量率。假设 ,动量项可以被视为用梯度下降优化以下目标的结果:
这种解释表明,动量实际上可以被视为一个元记忆(meta memory)模块,学习如何将目标的梯度记忆到其参数中。基于这种直觉,在 C.4 节中,我们展示了经过小幅修改的 Adam 是模型梯度的最佳联想记忆。接下来,我们展示这种视角如何导致设计更具表达力的优化器:
扩展:更具表达力的关联 (Extension: More Expressive Association)。 如前所述,动量是一个无值(value-less)的联想记忆,因此表达能力有限。为了解决这个问题,遵循联想记忆的原始定义(即,将键映射到值),我们令值参数 ,因此动量旨在最小化:
使用梯度下降,产生更新规则:
这个公式等同于使用预处理(preconditioning)的动量 GD。实际上,预处理意味着动量项是一个联想记忆,学习如何压缩 和梯度项 之间的映射。虽然任何合理的预处理选择(例如,随机特征)都可以提高 GD 的表达能力,带动量本身是一个无值记忆(即,将所有梯度映射到单个值),上述视角给出了关于什么预处理更有用的更多直觉。也就是说,动量作为一个记忆,旨在将梯度映射到其对应的值,因此梯度的函数(例如,关于 Hessian 的信息)可以为记忆提供更有意义的映射。
扩展:更具表达力的目标 (Extension: More Expressive Objectives)。 正如 Behrouz 等人 [58] 所讨论的,优化点积相似度的内部目标会导致类似 Hebbian 的更新规则,这可能导致记忆效率较低。这种内部目标的一个自然扩展是使用 回归损失(用于测量相应的键-值映射适应度)并最小化损失函数 ,产生更新规则:
此更新基于 delta-rule(Delta 规则)[64],因此它允许记忆(动量)更好地管理其有限的容量并更好地记忆过去的梯度序列。
扩展:更具表达力的记忆 (Extension: More Expressive Memory)。 如前所述,动量可以被视为一个元记忆模型,使用线性层(即,矩阵值)来压缩过去的梯度值。由于动量的线性性质,其内部目标只能学习过去梯度的线性函数。为了增加该模块的学习容量,一种替代方案是使用其他强大的持久学习模块:即,用 MLP 替换动量的线性矩阵值记忆。因此,动量作为过去梯度的记忆,具有更多容量来捕获梯度的潜在动态。为此,我们扩展方程 17 中的公式为:
其中 $\mathbf{u}_i = \nabla 且 是动量的内部目标(例如,点积相似度 )。我们将此变体称为 Deep Momentum Gradient Descent (DMGD,深度动量梯度下降)。
扩展:非线性输出 (Extension: None Linear Outputs)。 基于上述将动量视为神经架构的视角,增强动量记忆模块表示能力的一种常用技术是在其输出之上使用非线性 [28, 65]。也就是说,我们重新表述方程 23 为:
其中 是任意非线性。作为一个例子,我们令 ,其中 Newton-Schulz() 是迭代 Newton-Schulz 方法 [66],且 为线性层;得到的优化器等同于 Muon 优化器 [34]。
超越简单反向传播 (Going Beyond Simple Backpropagation)。 如前文 2.1 节所讨论的,预训练过程和反向传播是一种联想记忆形式,其中输入数据被映射到由其预测输出 引起的惊奇:
这从联想记忆的角度来看,等同于在以下优化过程中进行一步梯度下降:
正如我们在附录 C 中讨论的,上述公式导致忽略了像 这样的数据样本的依赖性。为了将其扩展为一个更强大的公式,使其也考虑数据点的依赖性(这在我们于 token 空间中使用优化器时非常重要,因为它们不是独立的),我们使用一步梯度下降的 回归目标,如下所示:
该公式导致了梯度下降的一种新变体,可以简化为:
稍后,我们将此优化器用作我们 HOPE 架构的内部优化器。
3. HOPE:具有连续统记忆的自指学习模块 (HOPE: A Self-Referential Learning Module with Continuum Memory)
现有的架构骨干包括 (1) 一个 working memory(工作记忆) 模块(例如,attention),负责融合整个序列长度上的信息,以及 (2) 一个前馈层(例如,MLP),融合特征间的信息并作为预训练阶段的 persistent memory(持久记忆) 或知识存储。从 NL 的角度来看,预训练是学习模块最外层在其受限 context flow 上更新的阶段。因此,在持续设置中,这种预训练阶段也随时间很少更新,其对应的知识存储也需要随时间很少更新。鉴于这种直觉,我们扩展了传统的“长期/短期记忆”系统的观点,并建议为每个 level(频率域)设置一个知识存储前馈层。
给定频率的定义,Continuum Memory System (CMS,连续统记忆系统) 被形式化为 MLP 块 的链,每个块关联一个 chunk size(块大小) ,使得给定输入 ,链的输出计算如下(为了清晰起见,我们忽略了归一化):
其中第 个 MLP 块的参数,即 ,每 步更新一次:
在附录 B.1 中,我们讨论了该公式的不同变体,包括完全嵌套的 MLP 层。这里 是对应于 的学习率,而 是任意优化器的误差分量(例如,梯度下降中的 )。传统的 Transformer 块 [27] 是此公式的一个特例,其中 。值得注意的是,方程 31 提供了一个重要的解释:参数 负责将其自身的上下文压缩到其参数中,因此它们是其上下文抽象知识的代表。
HOPE。我们进一步提出了一个基于 Titans [28] 和我们在 B.1 节中提到的梯度下降变体的自指学习(self-referential learning)模块。结合这个具有连续统记忆系统的自指序列模型,产生了 HOPE 架构。
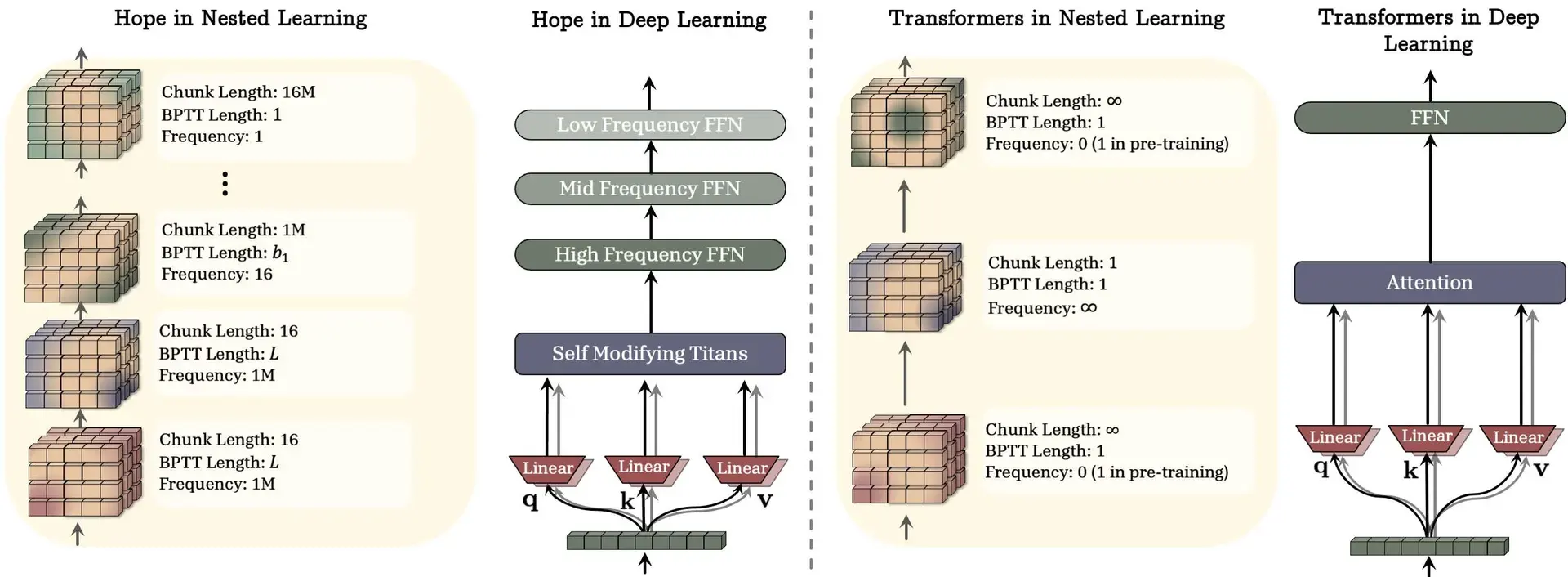 图 3:HOPE 架构主干与 Transformer 的对比
图 3:HOPE 架构主干与 Transformer 的对比
(为了清晰起见,已去除归一化及潜在的数据依赖组件)
| Model | Params / Tokens | Wiki. ppl ↓ | LMB. ppl ↓ | LMB. acc ↑ | PIQA acc ↑ | Hella. acc_n ↑ | Wino. acc ↑ | ARC-e acc ↑ | ARC-c acc_n ↑ | SIQA acc ↑ | BoolQ acc ↑ | Avg. ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HOPE (ours) | 760M / 30B | 26.05 | 29.38 | 35.40 | 64.62 | 40.11 | 51.19 | 56.92 | 28.49 | 38.33 | 60.12 | 46.90 |
| Transformer++ | 760M / 30B | 25.21 | 27.64 | 35.78 | 66.92 | 42.19 | 51.95 | 60.38 | 32.46 | 39.51 | 60.37 | 48.69 |
| RetNet | 760M / 30B | 26.08 | 24.45 | 34.51 | 67.19 | 41.63 | 52.09 | 63.17 | 32.78 | 38.36 | 57.92 | 48.46 |
| DeltaNet | 760M / 30B | 24.37 | 24.60 | 37.06 | 66.93 | 41.98 | 50.65 | 64.87 | 31.39 | 39.88 | 59.02 | 48.97 |
| TTT | 760M / 30B | 24.17 | 23.51 | 34.74 | 67.25 | 43.92 | 50.99 | 64.53 | 33.81 | 40.16 | 59.58 | 47.32 |
| Samba∗ | 760M / 30B | 20.63 | 22.71 | 39.72 | 69.19 | 47.35 | 52.01 | 66.92 | 33.20 | 38.98 | 61.24 | 51.08 |
| Titans (LMM) | 760M / 30B | 20.04 | 21.96 | 37.40 | 69.28 | 48.46 | 52.27 | 66.31 | 35.84 | 40.13 | 62.76 | 51.56 |
| HOPE (ours) | 1.3B / 100B | 20.53 | 20.47 | 39.02 | 70.13 | 49.21 | 52.70 | 66.89 | 36.05 | 40.71 | 63.29 | 52.26 |
| Transformer++ | 1.3B / 100B | 18.53 | 18.32 | 42.60 | 70.02 | 50.23 | 53.51 | 68.83 | 35.10 | 40.66 | 57.09 | 52.25 |
| RetNet | 1.3B / 100B | 19.08 | 17.27 | 40.52 | 70.07 | 49.16 | 54.14 | 67.34 | 33.78 | 40.78 | 60.39 | 52.02 |
| DeltaNet | 1.3B / 100B | 17.71 | 16.88 | 42.46 | 70.72 | 50.93 | 53.35 | 68.47 | 35.66 | 40.22 | 55.29 | 52.14 |
| Samba∗ | 1.3B / 100B | 16.13 | 13.29 | 44.94 | 70.94 | 53.42 | 55.56 | 68.81 | 36.17 | 39.96 | 62.11 | 54.00 |
| Titans (LMM) | 1.3B / 100B | 15.60 | 11.41 | 49.14 | 73.09 | 56.31 | 59.81 | 72.43 | 40.82 | 42.05 | 60.97 | 56.82 |
| HOPE (ours) | 1.3B / 100B | 15.11 | 11.63 | 50.01 | 73.29 | 56.84 | 60.19 | 72.30 | 41.24 | 42.52 | 61.46 | 57.23 |
表 1:HOPE 与基线模型在语言建模及常识推理任务上的性能表现
混合模型用 ∗ 标注。
4. 实验 (Experiments)
由于篇幅原因,在正文中,我们报告了 HOPE 在语言建模和常识推理任务上的评估结果。然而,我们在附录中报告了广泛的结果集,包括关于优化器、in-context learning 的涌现、HOPE 的持续学习能力、消融研究、长上下文任务等的实验。有关实验设置和其他使用数据集的详细信息见附录 G。
语言建模和常识推理 (Language Modeling and Common-sense Reasoning)。 我们遵循最近的序列建模研究 [28, 67, 68],并报告了 HOPE 与基线模型在 340M、760M 和 1.3B 规模下的语言建模以及常识推理下游任务的结果。这些结果在表 1 中报告。HOPE 在所有规模和基准任务中都表现出非常好的性能,优于 Transformers 和最近的现代循环神经网络(Recurrent Neural Networks),包括 Gated DeltaNet 和 Titans。将 HOPE 与 Titans 和 Gated DeltaNet 进行比较,我们可以看到,根据上下文动态改变键、值和查询投影以及深度记忆模块,可以在基准结果中产生具有更低困惑度(perplexity)和更高准确率的模型。
参考文献 (References)
[1] Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. Nested learning: The illusion of deep learning architectures. arXiv preprint arXiv.
[2] Walter Pitts. The linear theory of neuron networks: The dynamic problem. The bulletin of mathematical biophysics, 5:23–31, 1943.
[3] Warren S McCulloch. The brain computing machine. Electrical Engineering, 68(6):492–497, 1949.
[4] Warren S McCulloch and Walter Pitts. The statistical organization of nervous activity. Biometrics, 4(2):91–99, 1948.
[5] Arthur L Samuel. Some studies in machine learning using the game of checkers. IBM Journal of research and development, 3(3):210–229, 1959.
[6] David Silver and Richard S Sutton. Welcome to the era of experience. Google AI, 1, 2025.
[7] Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction, volume 1. 1998.
[8] Jonathan H. Connell and Sridhar Mahadevan. Robot learning. Robotica, 17(2):229–235, 1999. doi: 10.1017/S0263574799271172.
[9] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. nature, 521(7553):436–444, 2015.
[10] John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold. nature, 596(7873):583–589, 2021.
[11] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016.
[12] David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144, 2018.
[13] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
[14] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=YicbFdNTTy.
[15] Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025.
[16] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024.
[17] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[18] Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks. Advances in neural information processing systems, 27, 2014.
[19] Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos. Advances in neural information processing systems, 29, 2016.
[20] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
[21] William Merrill, Ashish Sabharwal, and Noah A Smith. Saturated transformers are constantdepth threshold circuits. Transactions of the Association for Computational Linguistics, 10: 843–856, 2022.
[22] Clayton Sanford, Daniel Hsu, and Matus Telgarsky. Transformers, parallel computation, and logarithmic depth. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=QCZabhKQhB.
[23] William Merrill, Jackson Petty, and Ashish Sabharwal. The illusion of state in state-space models. In Forty-first International Conference on Machine Learning, 2024. URL https: //openreview.net/forum?id=QZgo9JZpLq.
[24] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[25] Juergen Schmidhuber and Sepp Hochreiter. Long short-term memory. Neural Computation MIT-Press, 1997.
[26] Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological cybernetics, 36(4):193–202, 1980.
[27] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
[28] Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024.
[29] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
[30] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
[31] Shaden Alshammari, John Hershey, Axel Feldmann, William T Freeman, and Mark Hamilton. I-con: A unifying framework for representation learning. arXiv preprint arXiv:2504.16929, 2025.
[32] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bklr3j0cKX.
[33] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[34] K Jordan, Y Jin, V Boza, Y Jiacheng, F Cecista, L Newhouse, and J Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024b. URL https://kellerjordan. github. io/posts/muon, 2024.
[35] Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. In International Conference on Machine Learning, pages 1842–1850. PMLR, 2018.
[36] Nikhil Vyas, Depen Morwani, Rosie Zhao, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham M. Kakade. SOAP: Improving and stabilizing shampoo using adam for language modeling. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=IDxZhXrpNf.
[37] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[38] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[39] Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? Advances in neural information processing systems, 36:55565–55581, 2023.
[40] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=iaYcJKpY2B_.
[41] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. Advances in Neural Information Processing Systems, 36: 61501–61513, 2023.
[42] Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Tennien, Atri Rudra, James Zou, Azalia Mirhoseini, et al. Cartridges: Lightweight and generalpurpose long context representations via self-study. arXiv preprint arXiv:2506.06266, 2025.
[43] hongzhou yu, Tianhao Cheng, YingwenWang, Wen He, QingWang, Ying Cheng, Yuejie Zhang, Rui Feng, and Xiaobo Zhang. FinemedLM-o1: Enhancing medical knowledge reasoning ability of LLM from supervised fine-tuning to test-time training. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=7ZwuGZCopw.
[44] Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyothish Pari, Yoon Kim, and Jacob Andreas. The surprising effectiveness of test-time training for few-shot learning. In Forty-second International Conference on Machine Learning, 2024.
[45] William Beecher Scoville and Brenda Milner. Loss of recent memory after bilateral hippocampal lesions. Journal of neurology, neurosurgery, and psychiatry, 20(1):11, 1957.
[46] Alvaro Pascual-Leone, Amir Amedi, Felipe Fregni, and Lotfi B Merabet. The plastic human brain cortex. Annu. Rev. Neurosci., 28(1):377–401, 2005.
[47] Michael V Johnston. Plasticity in the developing brain: implications for rehabilitation. Developmental disabilities research reviews, 15(2):94–101, 2009.
[48] Akihiro Goto, Ayaka Bota, Ken Miya, Jingbo Wang, Suzune Tsukamoto, Xinzhi Jiang, Daichi Hirai, Masanori Murayama, Tomoki Matsuda, Thomas J. McHugh, Takeharu Nagai, and Yasunori Hayashi. Stepwise synaptic plasticity events drive the early phase of memory consolidation. Science, 374(6569):857–863, 2021. doi: 10.1126/science.abj9195. URL https://www.science.org/doi/abs/10.1126/science.abj9195. [49] Uwe Frey and Richard GM Morris. Synaptic tagging and long-term potentiation. Nature, 385 (6616):533–536, 1997.
[50] Wannan Yang, Chen Sun, Roman Huszár, Thomas Hainmueller, Kirill Kiselev, and György Buzsáki. Selection of experience for memory by hippocampal sharp wave ripples. Science, 383 (6690):1478–1483, 2024.
[51] Daoyun Ji and Matthew A Wilson. Coordinated memory replay in the visual cortex and hippocampus during sleep. Nature neuroscience, 10(1):100–107, 2007.
[52] Adrien Peyrache, Mehdi Khamassi, Karim Benchenane, Sidney I Wiener, and Francesco P Battaglia. Replay of rule-learning related neural patterns in the prefrontal cortex during sleep. Nature neuroscience, 12(7):919–926, 2009.
[53] David J Foster and Matthew AWilson. Reverse replay of behavioural sequences in hippocampal place cells during the awake state. Nature, 440(7084):680–683, 2006.
[54] Sean PA Drummond, Gregory G Brown, J Christian Gillin, John L Stricker, Eric C Wong, and Richard B Buxton. Altered brain response to verbal learning following sleep deprivation. Nature, 403(6770):655–657, 2000.
[55] Seung-Schik Yoo, Peter T Hu, Ninad Gujar, Ferenc A Jolesz, and Matthew P Walker. A deficit in the ability to form new human memories without sleep. Nature neuroscience, 10(3):385–392, 2007.
[56] W Scott Terry. Learning and memory: Basic principles, processes, and procedures. Routledge, 2017.
[57] Hideyuki Okano, Tomoo Hirano, and Evan Balaban. Learning and memory. Proceedings of the National Academy of Sciences, 97(23):12403–12404, 2000.
[58] Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online optimization. arXiv preprint arXiv:2504.13173, 2025.
[59] Bo Liu, Rui Wang, Lemeng Wu, Yihao Feng, Peter Stone, and Qiang Liu. Longhorn: State space models are amortized online learners. arXiv preprint arXiv:2407.14207, 2024.
[60] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR, 2020.
[61] Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023.
[62] Juergen Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. accepted for publication in. Neural Computation, 1992.
[63] Imanol Schlag, Kazuki Irie, and Juergen Schmidhuber. Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning, pages 9355–9366. PMLR, 2021.
[64] DL Prados and SC Kak. Neural network capacity using delta rule. Electronics Letters, 25(3): 197–199, 1989.
[65] Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620, 2024.
[66] Nicholas J Higham. Functions of matrices: theory and computation. SIAM, 2008.
[67] Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. arXiv preprint arXiv:2412.06464, 2024.
[68] Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. Advances in Neural Information Processing Systems, 37:115491–115522, 2024.
[69] Matteo Tiezzi, Michele Casoni, Alessandro Betti, Tommaso Guidi, Marco Gori, and Stefano Melacci. On the resurgence of recurrent models for long sequences: Survey and research opportunities in the transformer era. arXiv preprint arXiv:2402.08132, 2024.
[70] Bo Peng, Eric Alcaide, Quentin Gregory Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Nguyen Chung, Leon Derczynski, Xingjian Du, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartłomiej Koptyra, Hayden Lau, Jiaju Lin, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Guangyu Song, Xiangru Tang, Johan S. Wind, Stanisław Wozniak, Zhenyuan Zhang, Qinghua Zhou, Jian Zhu, and Rui-Jie Zhu. RWKV: Reinventing RNNs for the transformer era. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id=7SaXczaBpG.
[71] Jimmy T.H. Smith, Andrew Warrington, and Scott Linderman. Simplified state space layers for sequence modeling. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Ai8Hw3AXqks.
[72] Ramin Hasani, Mathias Lechner, Tsun-Hsuan Wang, Makram Chahine, Alexander Amini, and Daniela Rus. Liquid structural state-space models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id= g4OTKRKfS7R.
[73] Ali Behrouz, Michele Santacatterina, and Ramin Zabih. Mambamixer: Efficient selective state space models with dual token and channel selection. arXiv preprint arXiv:2403.19888, 2024.
[74] Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Xingjian Du, Teddy Ferdinan, Haowen Hou, et al. Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892, 2024.
[75] Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Haowen Hou, Janna Lu, William Merrill, Guangyu Song, Kaifeng Tan, Saiteja Utpala, et al. Rwkv-7" goose" with expressive dynamic state evolution. arXiv preprint arXiv:2503.14456, 2025.
[76] Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Increasing the expressivity of deltanet through products of householders. arXiv preprint arXiv:2502.10297, 2025.
[77] John J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982.
[78] Juergen Schmidhuber. Reducing the ratio between learning complexity and number of time varying variables in fully recurrent nets. In ICANN’93: Proceedings of the International Conference on Artificial Neural Networks Amsterdam, The Netherlands 13–16 September 1993 3, pages 460–463. Springer, 1993.
[79] Donald Olding Hebb. The organization of behavior: A neuropsychological theory. Psychology press, 2005.
[80] Tsendsuren Munkhdalai and Hong Yu. Neural semantic encoders. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 1, page 397. NIH Public Access, 2017.
[81] Tsendsuren Munkhdalai, Alessandro Sordoni, Tong Wang, and Adam Trischler. Metalearned neural memory. Advances in Neural Information Processing Systems, 32, 2019.
[82] Kazuki Irie, Imanol Schlag, Robert Csordas, and Juergen Schmidhuber. Going beyond linear transformers with recurrent fast weight programmers. Advances in neural information processing systems, 34:7703–7717, 2021.
[83] Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test-time regression: a unifying framework for designing sequence models with associative memory. arXiv preprint arXiv:2501.12352, 2025.
[84] Kazuki Irie, Robert Csordas, and Juergen Schmidhuber. The dual form of neural networks revisited: Connecting test time predictions to training patterns via spotlights of attention. In International Conference on Machine Learning, pages 9639–9659. PMLR, 2022.
[85] Kazuki Irie, Imanol Schlag, Róbert Csordás, and Juergen Schmidhuber. A modern selfreferential weight matrix that learns to modify itself. In International Conference on Machine Learning, pages 9660–9677. PMLR, 2022.
[86] Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, and Dimitris Papailiopoulos. Can mamba learn how to learn? a comparative study on in-context learning tasks. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=GbFluKMmtE.
[87] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations, 2017. URL https:// openreview.net/forum?id=Byj72udxe.
[88] Denis Paperno, German Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernandez. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Katrin Erk and Noah A. Smith, editors, Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1525–1534, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v1/P16-1144. URL https://aclanthology.org/P16-1144/.
[89] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
[90] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluis Marquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URL https://aclanthology.org/P19-1472/.
[91] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
[92] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
[93] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social IQa: Commonsense reasoning about social interactions. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463–4473, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1454. URL https://aclanthology.org/D19-1454/.
[94] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1300. URL https://aclanthology.org/N19-1300/.
[95] Michael Poli, Armin W Thomas, Eric Nguyen, Pragaash Ponnusamy, Björn Deiseroth, Kristian Kersting, Taiji Suzuki, Brian Hie, Stefano Ermon, Christopher Ré, et al. Mechanistic design and scaling of hybrid architectures. arXiv preprint arXiv:2403.17844, 2024.