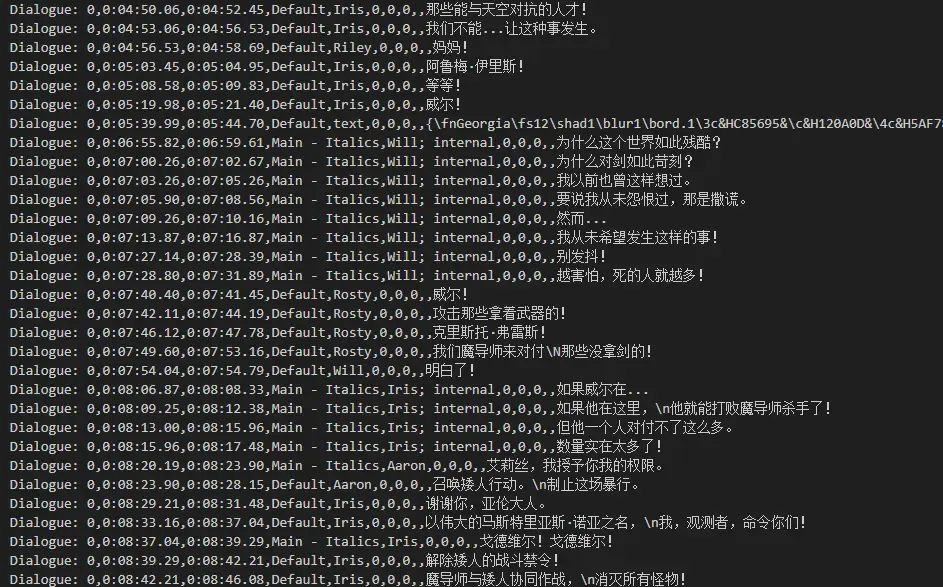
我很喜欢杖与剑的魔剑谭这部作品,所以每周都会在周日下午四点半时追最新一集。baha当然可以直接看,但分辨率和码率都不高,而等国内的汉化组也需要一段时间,所以我最终选择了国外CR源的资源,以最新的第二集为例,这是它在mediainfo上的信息:
 我对其画面是很满意的,但其英文字幕却是个问题……我经过工具将里面的ass文件提取出来后,曾尝试将其直接交给AI让其翻译,但困于上下文长度,它(ChatGPT&Gemini)只能分批次返回,这样子实在是太繁琐了,而且后面它也开始瞎编乱造了。我考虑到是ass文件里的时间轴等“无用信息”占用了AI的记忆,我最好只给它一份干净的、只含需要翻译文本的txt,但难道我要先把整个ass扔给AI,让它提取出txt,我再将txt喂给它吗?这也是繁琐——于是我选择了自己来干前一步。
我对其画面是很满意的,但其英文字幕却是个问题……我经过工具将里面的ass文件提取出来后,曾尝试将其直接交给AI让其翻译,但困于上下文长度,它(ChatGPT&Gemini)只能分批次返回,这样子实在是太繁琐了,而且后面它也开始瞎编乱造了。我考虑到是ass文件里的时间轴等“无用信息”占用了AI的记忆,我最好只给它一份干净的、只含需要翻译文本的txt,但难道我要先把整个ass扔给AI,让它提取出txt,我再将txt喂给它吗?这也是繁琐——于是我选择了自己来干前一步。
ass文件中的样例:
Dialogue: 0,0:00:05.85,0:00:08.72,Main - Italics,Will; internal,0,0,0,,Magic circles for gates \Nlike we saw on floor 11?
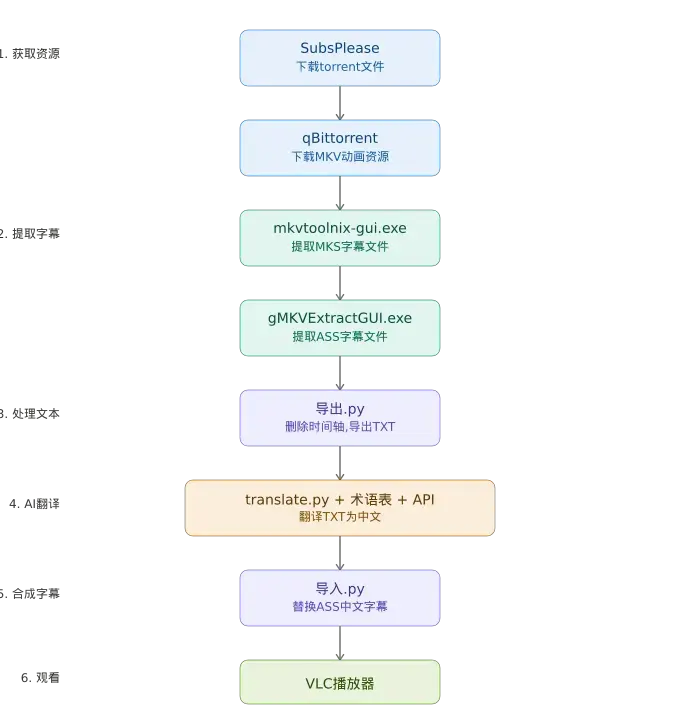
流程图如下:
以下是AI制作的代码部分:
导出.py:
#导出.py
Pythonimport os import re import glob def process_ass_file(file_path): """处理单个 ASS 文件,提取对话行并去除样式标签,输出到同名的 _export.txt 文件""" output_file = os.path.splitext(file_path)[0] + "_export.txt" try: with open(file_path, 'r', encoding='utf-8') as f: lines = f.readlines() extracted_lines = [] for line in lines: if line.startswith('Dialogue:'): parts = line.split(',', 9) if len(parts) >= 10: text = parts[9].rstrip('\n') # 移除花括号内的样式标签,如 {\fnArial\b1} plain = re.sub(r'\{[^}]*\}', '', text) extracted_lines.append(plain) if extracted_lines: with open(output_file, 'w', encoding='utf-8') as out: out.write('\n'.join(extracted_lines)) print(f"成功处理:{os.path.basename(file_path)} -> {os.path.basename(output_file)}") else: print(f"警告:{os.path.basename(file_path)} 中没有找到 Dialogue 行") except Exception as e: print(f"处理文件 {os.path.basename(file_path)} 时出错:{e}") def main(): # 获取脚本所在目录(与 .bat 和 .ass 文件同目录) script_dir = os.path.dirname(os.path.abspath(__file__)) ass_files = glob.glob(os.path.join(script_dir, "*.ass")) if not ass_files: print("当前目录下没有找到 .ass 文件") return print(f"找到 {len(ass_files)} 个 ASS 文件,开始处理...") for ass_file in ass_files: process_ass_file(ass_file) print("全部处理完毕") if __name__ == "__main__": main()
#导入.py
pythonimport os import re import glob def replace_first_plain(text, replacement): """将 text 中的第一个非样式标签的纯文本替换为 replacement,保留样式标签""" replaced = False def repl(m): nonlocal replaced if replaced or m.group(0).startswith('{'): return m.group(0) replaced = True return replacement return re.sub(r'(\{[^}]*\}|[^{]+)', repl, text) def process_ass_with_export(ass_path, export_path, output_path=None): """使用 export_path 中的行替换 ass_path 中的 Dialogue 文本,输出到 output_path""" if output_path is None: output_path = os.path.splitext(ass_path)[0] + "_output.ass" try: # 读取 ASS 文件 with open(ass_path, 'r', encoding='utf-8') as f: lines = f.readlines() # 读取导出的文本(每行是一个对话的纯文本) with open(export_path, 'r', encoding='utf-8') as ef: export_lines = [line.rstrip('\n') for line in ef] idx = 0 with open(output_path, 'w', encoding='utf-8') as out: for line in lines: if line.startswith('Dialogue:'): parts = line.split(',', 9) if len(parts) >= 10 and idx < len(export_lines): orig_text = parts[9] # 将 export 行中的换行符转换为 ASS 的 \N new_plain = export_lines[idx].replace('\n', r'\N') # 替换第一个纯文本区域,保留样式标签 new_text = replace_first_plain(orig_text, new_plain) parts[9] = new_text + '\n' line = ','.join(parts) idx += 1 out.write(line) print(f"成功处理:{os.path.basename(ass_path)} -> {os.path.basename(output_path)} (使用了 {os.path.basename(export_path)})") return True except Exception as e: print(f"处理 {os.path.basename(ass_path)} 时出错:{e}") return False def main(): script_dir = os.path.dirname(os.path.abspath(__file__)) ass_files = glob.glob(os.path.join(script_dir, "*.ass")) if not ass_files: print("当前目录下没有找到 .ass 文件") return processed_count = 0 for ass_path in ass_files: base_name = os.path.splitext(ass_path)[0] # 自动匹配同名的 _export_translate.txt 文件 export_path = base_name + "_export_translate.txt" if not os.path.exists(export_path): print(f"警告:未找到 {os.path.basename(ass_path)} 对应的导出文件 {os.path.basename(export_path)},跳过") continue print(f"处理:{os.path.basename(ass_path)} <-> {os.path.basename(export_path)}") if process_ass_with_export(ass_path, export_path): processed_count += 1 print(f"\n处理完成!共处理 {processed_count} 个文件,跳过 {len(ass_files) - processed_count} 个(缺少导出文件)") if __name__ == "__main__": main()
#translate.py
pythonimport requests # ========== 配置 ========== BASE_URL = "" API_KEY = "" MODEL = "" GLOSSARY_PATH = "" #术语表路径 INPUT_PATH = "" #导入的txt文件路径 # ========================== def translate(text, glossary): prompt = f"参照术语表翻译成中文,保持原文的换行格式,每行单独翻译,直接输出翻译结果:\n\n术语表:\n{glossary}\n\n待翻译:\n{text}" if glossary else f"翻译成中文,保持原文的换行格式,每行单独翻译:\n{text}" #这段prompt可自行修改 response = requests.post( f"{BASE_URL}/chat/completions", headers={"Authorization": f"Bearer {API_KEY}"}, json={"model": MODEL, "messages": [{"role": "user", "content": prompt}], "max_tokens": 8000} ) return response.json()['choices'][0]['message']['content'].strip() glossary = open(GLOSSARY_PATH, 'r', encoding='utf-8').read() if GLOSSARY_PATH else "" text = open(INPUT_PATH, 'r', encoding='utf-8').read() result = translate(text, glossary) with open(INPUT_PATH.replace('.txt', '_translated.txt'), 'w', encoding='utf-8') as f: f.write(result) print("完成!")
#术语表(参照了汉化组的)
csvSource,Translation Elfie,爱尔菲 Will Serfort,威尔·赛尔佛特 Lihanna,莉亚娜 book-learner,书呆子 no-talent,无能者 Workner,瓦克纳 Eliza,伊丽莎 Rosty,罗斯提 Edward,爱德沃 Colette,珂蕾特 Headmistress Caldron,珂德伦学院长 Naberous,纳贝鲁斯 the tower,塔 Sion,席翁 Wignall,伊格诺尔 elf,妖精 the Magia Vander,至高五杖 Albis Vina,冰姬之杖 Lady Elfaria,爱尔法利亚大人 Idleness Incarnate,怠惰的化身 recluse,家里蹲 Ellenor,艾尔诺 the magic competition,魔法对决 Barbarian,野蛮人 brazen harridans,泼妇们 Terminalia,境界祭 Ed,爱德 the Wand Graveyard,杖的墓地 Julius,尤里乌斯 Clairie,克蕾露薇 The Great Light Sovereign,光皇 Lord Aaron,亚隆大人 Lord Cariot,卡里奥特大人 "My bro, Zeo",泽奥大哥 Huzzah for Lady Ellenor,艾尔诺大人万岁 Flame Crown,炎之王冠 Water Orb,水之宝珠 Lightning Throne,雷之玉座 Wind Scepter,风之权杖 I offer the Earth Altar,献上大地之祭坛 "Open, o primordial darkness",辟开原初之黑暗 Supreme Spell,大术式 Vendes Terminalia,隔绝乐园的五杖之大境界 Mercedes,梅尔赛德斯 Rigarden,利加甸 Dinoboroses,迪诺波罗斯 high mages of the tower,塔的高级魔导士 meges,魔导士 monsters,魔物 mage slayer,魔导士杀手 Great Barrier,大结界 the Celestial Host,天上的侵略者 the Sleime,狩魔剑 Grand Duke,邪灵公爵 Devander,迪文德 the traces from the monsters,魔素 Wistoria,魔剑谭 One Single Magic Spell,独一无二的魔法 The laggard,吊车尾
最后呈现的结果还是挺满意的