


前一阵子写了一个cf worker用于b2的下载鉴权(参考了kun的这篇文章 使用 Cloudflare Workers 实现 B2 私有存储桶文件下载 | KUN's Blog),实现的效果就是
传入:文件路径
输出:签名完成后的下载链接
鉴权部分参考了b2的文档
Download Files with the Native API
Download Your Desired File From the Backblaze Cloud by Name
参考代码如下
async function handleAuthRequest(request) {
// 处理预检
if (request.method === "OPTIONS") {
return new Response(null, {
status: 204,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET, OPTIONS",
"Access-Control-Allow-Headers": "Content-Type, X-Gal-Id, X-User-Id, X-Timestamp, X-Signature",
"Access-Control-Max-Age": "86400"
}
})
}
// 验证请求
const validation = await validateRequest(request)
if (!validation.valid) {
return new Response(JSON.stringify({
success: false,
error: validation.error,
message: '未授权的请求'
}), {
status: 403,
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
}
})
}
try {
const url = new URL(request.url)
const filePath = url.searchParams.get('path')
if (!filePath) {
return new Response(JSON.stringify({
success: false,
error: "missing required query",
message: '缺少文件路径参数'
}), {
status: 400,
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
}
})
}
// 获取 B2 令牌
const urlData = await createShortLivedUrl(filePath)
const b2Token = urlData.authorizationToken
// 最终的下载URL
const downloadUrl = `https://file-download-cfcdn-02.yurari.moe/${filePath}?Authorization=${b2Token}`
return new Response(JSON.stringify({
success: true,
downloadUrl: downloadUrl
}), {
status: 200,
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
}
})
} catch (error) {
console.error("生成下载链接失败:", error)
return new Response(JSON.stringify({
success: false,
error: "生成下载链接失败: " + error.message
}), {
status: 500,
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
}
})
}
}
这个worker一直运行良好,直到我今天碰到了这个文件
[140425][スミレ] 夏恋ハイプレッシャー 予約特典同梱 ソフマップ特典CD (iso+mds+wav+cue+rr3).rar
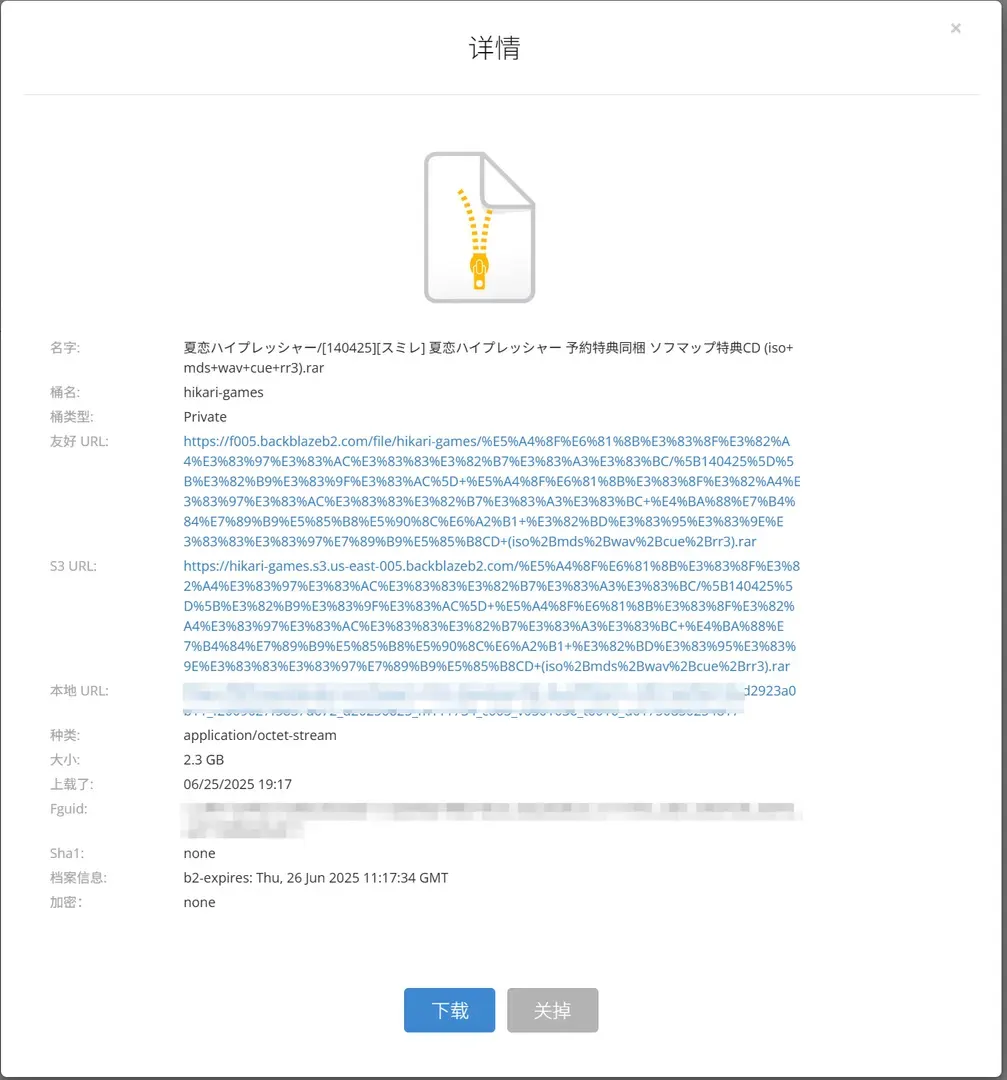 请求下载链接的步骤依旧没有出现任何问题(
请求下载链接的步骤依旧没有出现任何问题(也就是说整个签名步骤是正常的,划重点),但是使用返回的下载链接进行下载时就出现问题了,显示
{
"code": "invalid_request",
"message": "",
"status": 400
}
我第一时间想到的就是各种字符的编码问题,因为最初的代码中,filePath 是没有进行任何编码的字符串,前端传过来什么就是什么,所以我就使用了encodeURI(filePath)对filePath 进行了一次编码,修改后是这个样子
const url = new URL(request.url)
const filePath = url.searchParams.get('path')
const encodedFilePath = encodeURI(filePath)
const urlData = await createShortLivedUrl(encodedFilePath)
const b2Token = urlData.authorizationToken
const downloadUrl = `https://file-download-cfcdn-02.yurari.moe/${encodedFilePath}?Authorization=${b2Token}`
但是遗憾的是,这样修改后,不仅这个文件会出现问题,正常的文件也出现问题了,全部变成了签名验证失败(403)
经过我的一番折腾,发现问题在于:B2授权用的路径和最终下载URL的路径编码格式不一致
于是我尝试分离这两个步骤:
const url = new URL(request.url)
const filePath = url.searchParams.get('path')
const encodedFilePath = encodeURI(filePath)
// 授权用原始路径
const urlData = await createShortLivedUrl(filePath)
const b2Token = urlData.authorizationToken
// 下载URL用编码路径
const downloadUrl = `https://file-download-cfcdn-02.yurari.moe/${encodedFilePath}?Authorization=${b2Token}`
这样修改后,不带+号的文件恢复正常了,但带+号的文件还是404:
{
"code": "not_found",
"message": "File with such name does not exist.",
"status": 404
}
经过一波debug,我发现了一个非常隐蔽的问题:URLSearchParams.get()会自动将查询参数中的+号解释为空格!!!
这是Web标准中的行为,在application/x-www-form-urlencoded格式中,+号就是用来表示空格的。所以:
原始文件名: file+(iso+mds).rar
经过 URLSearchParams.get() 后变成: file (iso mds).rar
这就解释了为什么B2能正常授权(因为B2也能处理带空格的路径),但下载时找不到文件(因为实际文件名是带+号的)
解决方案
最终的解决方案是手动解析查询参数,避免+号被自动转换
const url = new URL(request.url)
let filePath = null
const queryString = url.search.substring(1) // 去掉开头的?
for (const pair of queryString.split('&')) {
const equalIndex = pair.indexOf('=')
if (equalIndex > 0) {
const key = pair.substring(0, equalIndex)
const value = pair.substring(equalIndex + 1)
if (key === 'path') {
// 手动解码,但不把+号当作空格处理
filePath = decodeURIComponent(value.replace(/+/g, '%2B')).replace(/%2B/g, '+')
break
}
}
}
// B2授权用原始路径(含真实+号)
const urlData = await createShortLivedUrl(filePath)
const b2Token = urlData.authorizationToken
// 下载URL用B2兼容的编码格式
const encodedPath = filePath.split('/').map(segment => {
return encodeURIComponent(segment).replace(/%20/g, '+')
}).join('/')
const downloadUrl = `https://file-download-cfcdn-02.yurari.moe/${encodedPath}?Authorization=${b2Token}`
B2的编码规则总结
根据B2官方文档和实际测试,B2使用的编码规则是
- 空格 → 编码为
+ - 真实的+号 → 编码为
%2B - 路径分隔符 / → 保持不变
- 其他特殊字符 → 标准URL编码
这种编码方式类似于application/x-www-form-urlencoded格式
参考:
Native API String Encoding
坑点总结
- URLSearchParams的隐蔽行为 - 会自动将
+号转换为空格,这是符合Web标准的,但容易被忽略 - B2路径编码的特殊性 - 不是标准的
encodeURI()格式,需要特殊处理 - 授权路径≠下载URL路径 - 两个阶段需要使用不同格式的路径
教训
- 处理文件路径时要特别注意特殊字符的编码问题
- 不同系统对URL编码的处理可能不一致,需要根据具体场景调整
- 遇到问题时要从最基础的参数解析开始排查
- 永远不要相信
URLSearchParams.get()能正确处理包含+号的参数值
最终这个问题得到了完美解决,现在无论文件名包含什么特殊字符都能正常下载了。希望这个踩坑经历能帮到遇到类似问题的友友们!



2 条回复