


本文重点在于制作映射表格以快速对CXDECExtracter提取的游戏文件分类重命名
本文参考:
https://www.kungal.com/topic/2670
使用项目提到的lst映射:
https://github.com/MLChinoo/hxv4_deobf_tools
Steamless:
https://github.com/atom0s/Steamless
撞库程序源码:
https://github.com/YuriSizuku/GalgameReverse/blob/master/project/krkr/src/krkr_hxv4_dumphash.cpp
XP3静态解析文档参考:
https://github.com/Kinotern/cxdec-hxv4-static-analysis
lst生成扫描思路:
静态提取XP3
无需运行时
Releases · Kinotern/CXdecStaticExtractor
rust语言开发,可批量解包
请在方案库填写会社/游戏/子版本
然后在解包队列选择你相应的游戏即可
lst需要自行维护,当前版本创建lst生成的映射暂未确认能否解包
无lst解包则只能解包出无名纯hash文件
运行时解包:
如果是steam游戏请看下面的脱壳与替换dll教学
https://github.com/Kinotern/KrkrExtractForCxdecV2Extra
Steam的KrKr游戏预处理
后续如果需要
实时dump获取这个映射lst表需要去掉壳子
所需的文件在
https://github.com/Kinotern/CXDECNameRipper/tree/main/Steam去除drm
如果不想这么麻烦可以选择下HF商城的官中,有一些游戏在HF暂未提供下载
如魔女的夜宴
Steamless脱壳
Steamless打开游戏exe
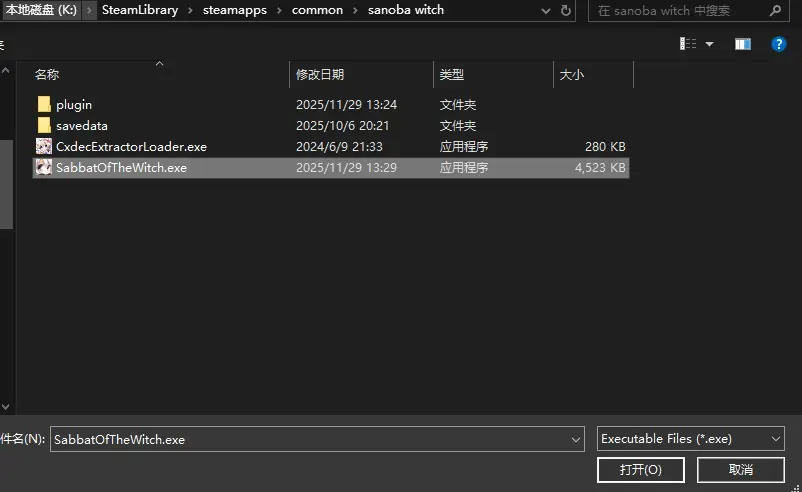
选1257项
点Unpack File
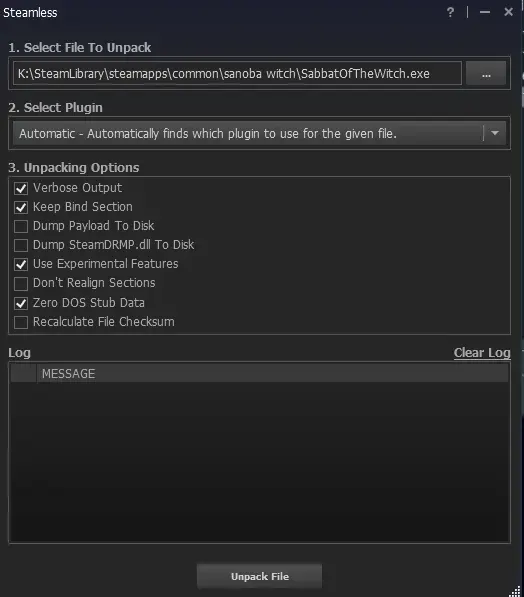 出现绿色字,提取成功
出现绿色字,提取成功
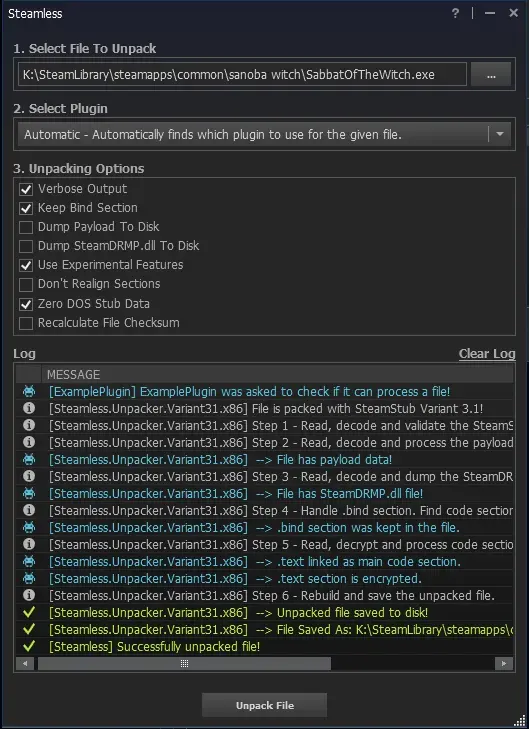 游戏目录会有一个叫SabbatOfTheWitch.exe.unpacked.exe
游戏目录会有一个叫SabbatOfTheWitch.exe.unpacked.exe
替换api(项目文件已含此dll)
将steamapi.dll覆盖过去
Dracu-Riot不要用steamapi64.dll来提取,应该是使用32位版本的程序提取
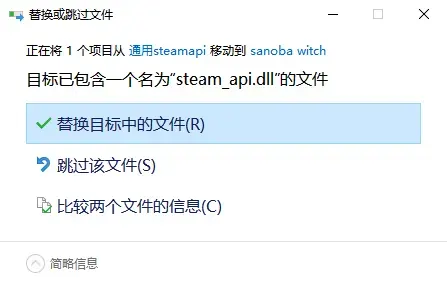
覆盖后报错直接打开是正常的
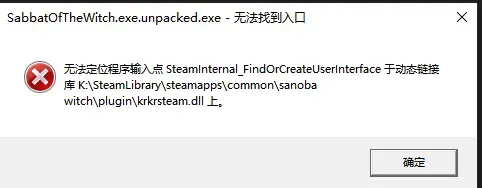
然后出现弹窗Malformed exe/dll detected或无法找到入口
原因是没绕过程序startup.tjs的if link fail逻辑
本文编写的小工具可以解决大多数这样的问题
并测试了魔女的夜宴,星光咖啡馆,病弱妹,DR,LLLJ这几个游戏都可以patch掉
其他若失败请提出issue
https://github.com/Kinotern/CXDECNameRipper/tree/main/去除MFD弹窗
实时dump与运行时
顺带找到名字恢复请看如下
https://github.com/Kinotern/KrkrExtractForCxdecV2Extra
走完游戏流程不一定百分百能恢复,但是把大部分都恢复好了
结束游戏前请点击停止实时恢复按钮
撞库确认此项存在
创建一个files.txt
里头写入如下字段或许你要撞库确认的话
编码建议为utf-16le
base.stage
cglist.csv
soundlist.csv
charvoice.csv
imagediffmap.csv
savelist.csv
scenelist.csv
replay.ks
_chthum_index.pbd
......
将version.dll(切记不要与kirikiritools的dll混在一起二者注入的东西不一样)
复制到游戏目录
打开游戏
然后打开游戏后出现弹窗有东西在闪就是在撞库了
等待一会后
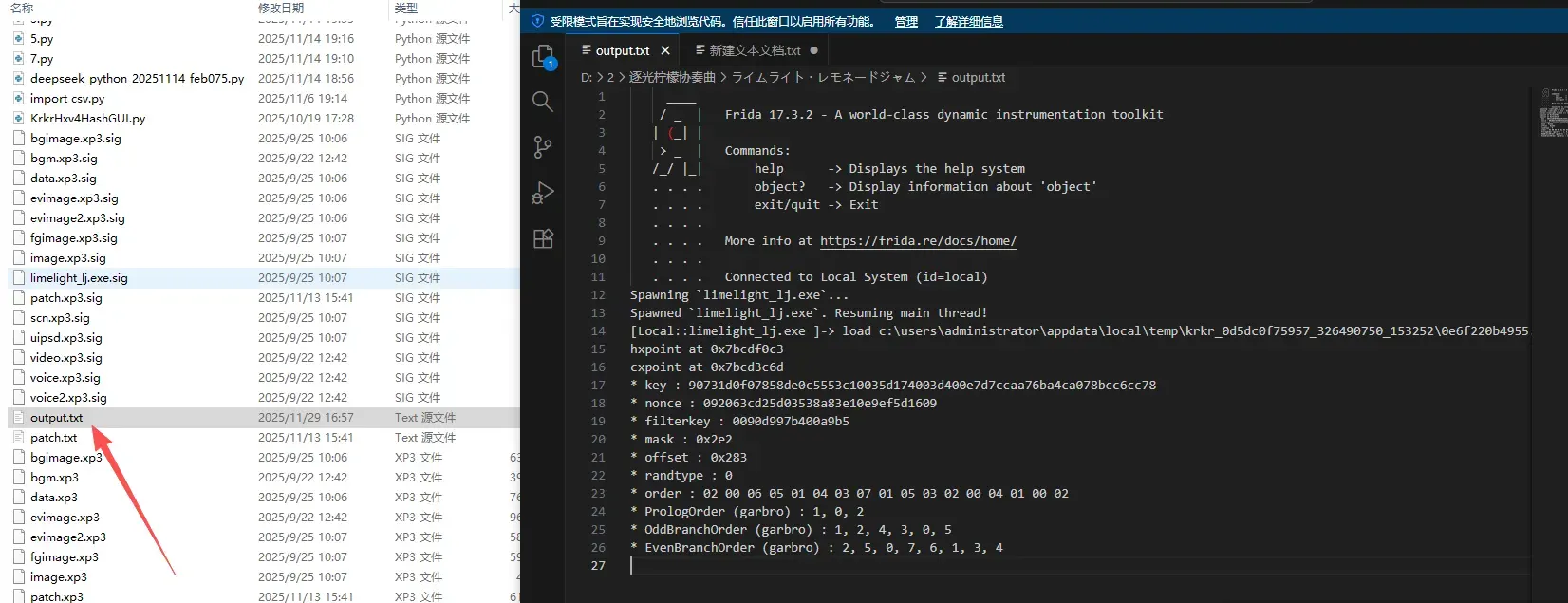
[src/krkr_hxv4_dumphash.cpp,216,calc_thread,I] try to calc names in dirs.txt [src/krkr_hxv4_dumphash.cpp,218,calc_thread,I] calculate finish, results in files_match.txt, dirs_match.txt
直接关掉命令窗口就可以快速关掉游戏了
即可在游戏目录找到files_match.txt与dirs_match.txt
里头记载着撞库得到的信息


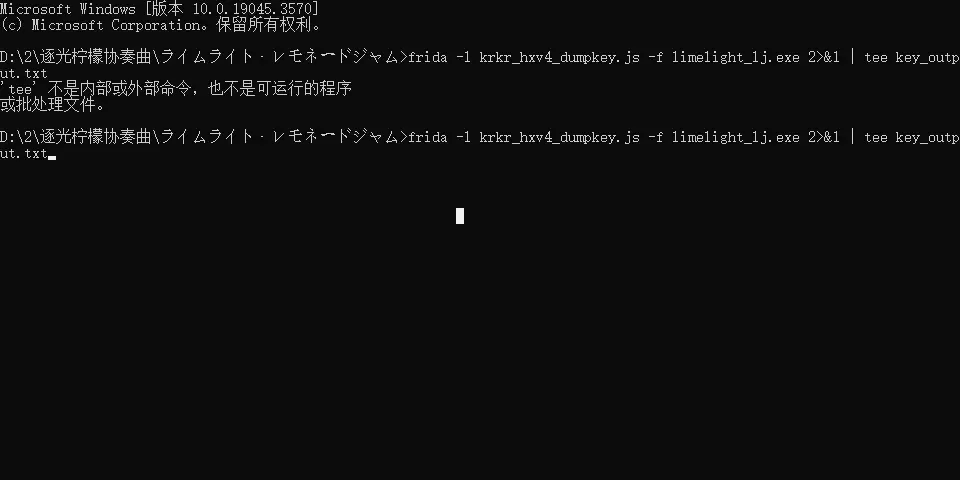 大佬我是少东西了吗?为啥说tee不是命令?
大佬我是少东西了吗?为啥说tee不是命令?
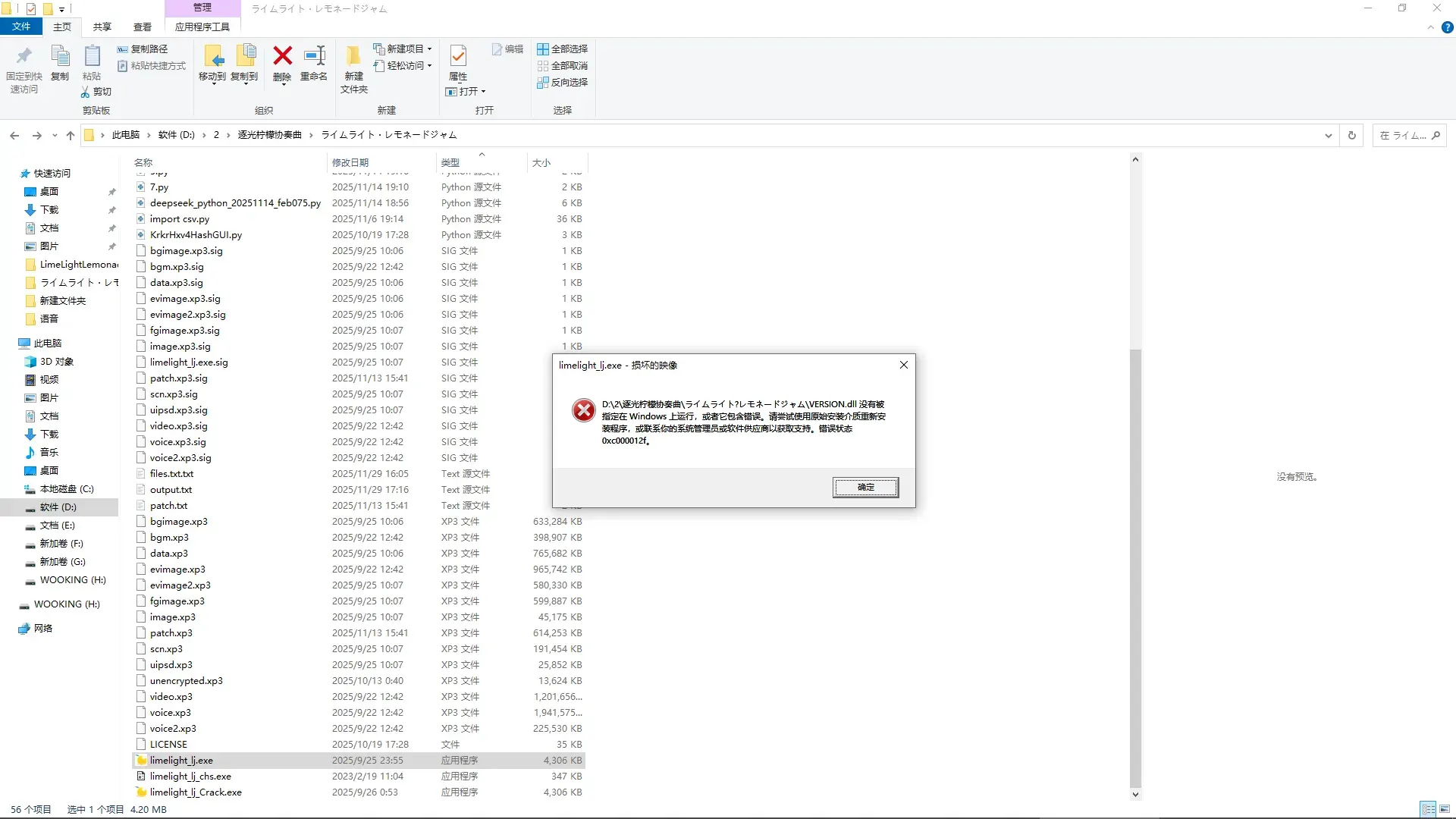 更改了version.dll好像无法运行游戏了#
更改了version.dll好像无法运行游戏了#
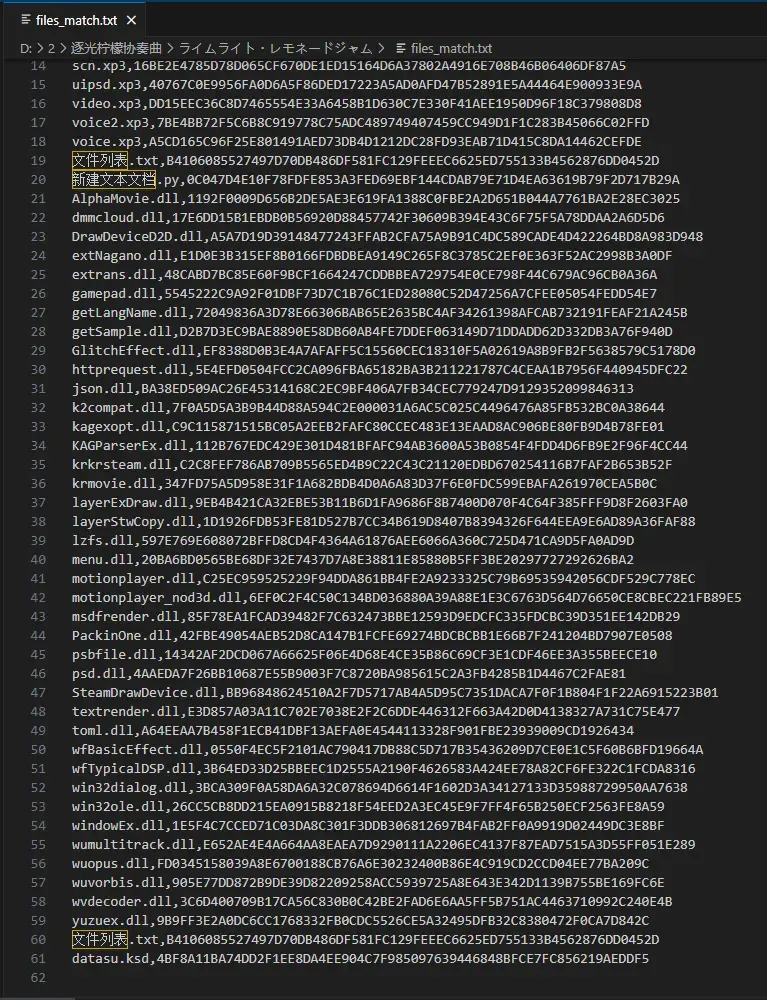 files_match.txt只有60条是正常的吗
files_match.txt只有60条是正常的吗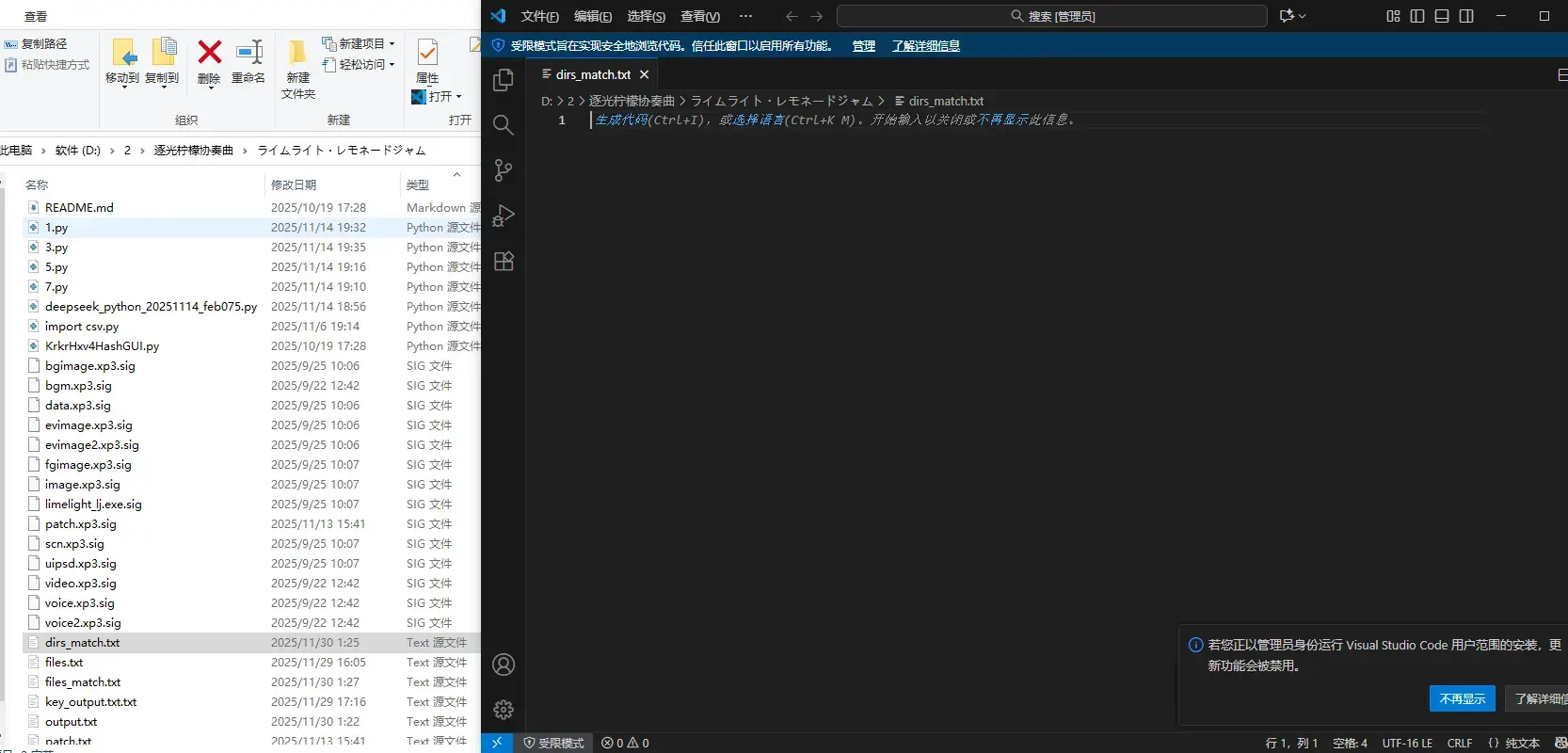 dirs_match.txt里面是空的
dirs_match.txt里面是空的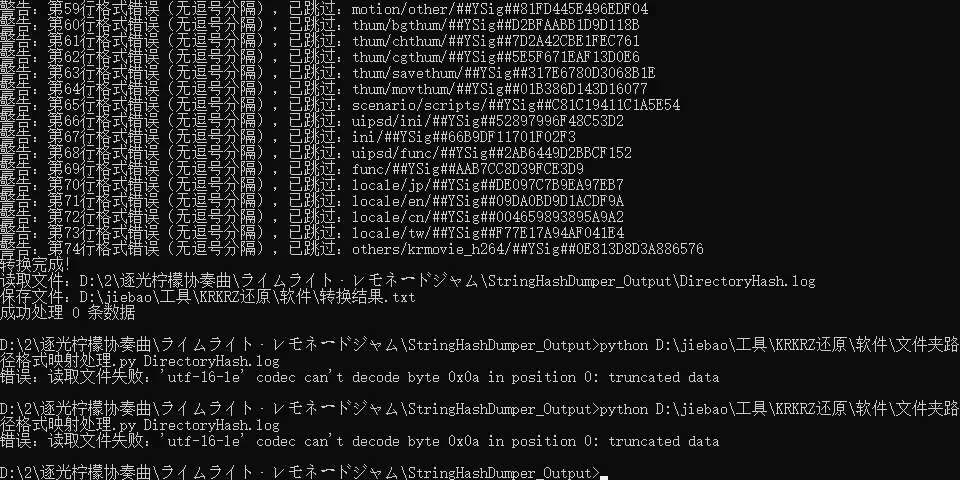 这些都是正常的吗?~
这些都是正常的吗?~
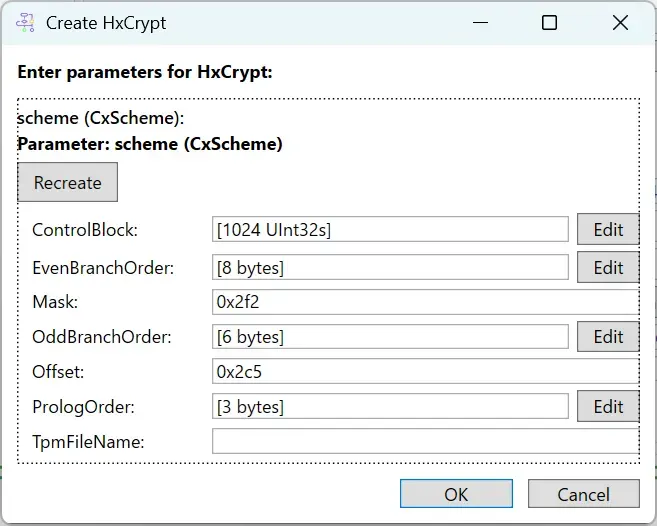 它却显示
它却显示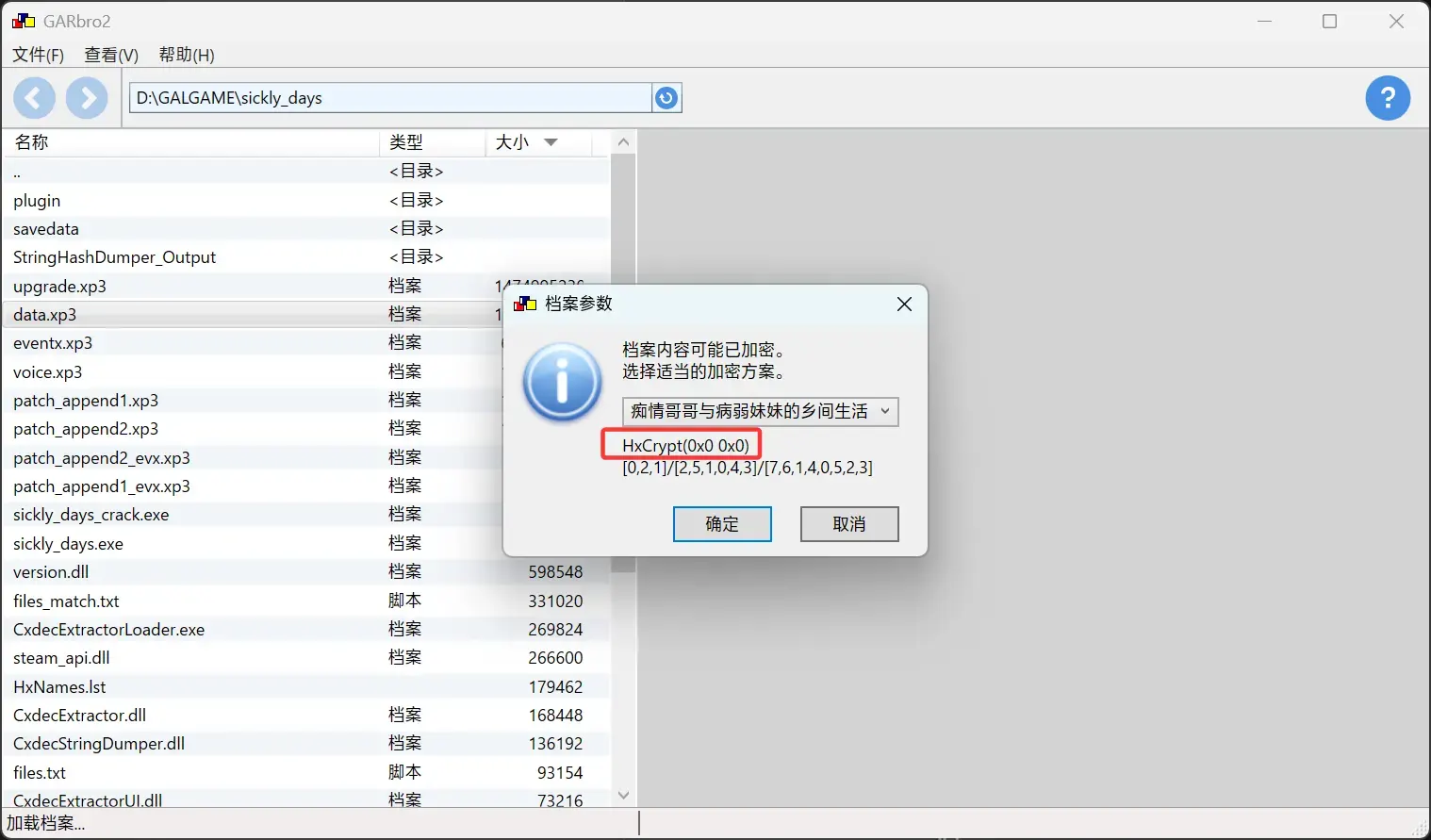 目前是文件夹名已经还原状态
目前是文件夹名已经还原状态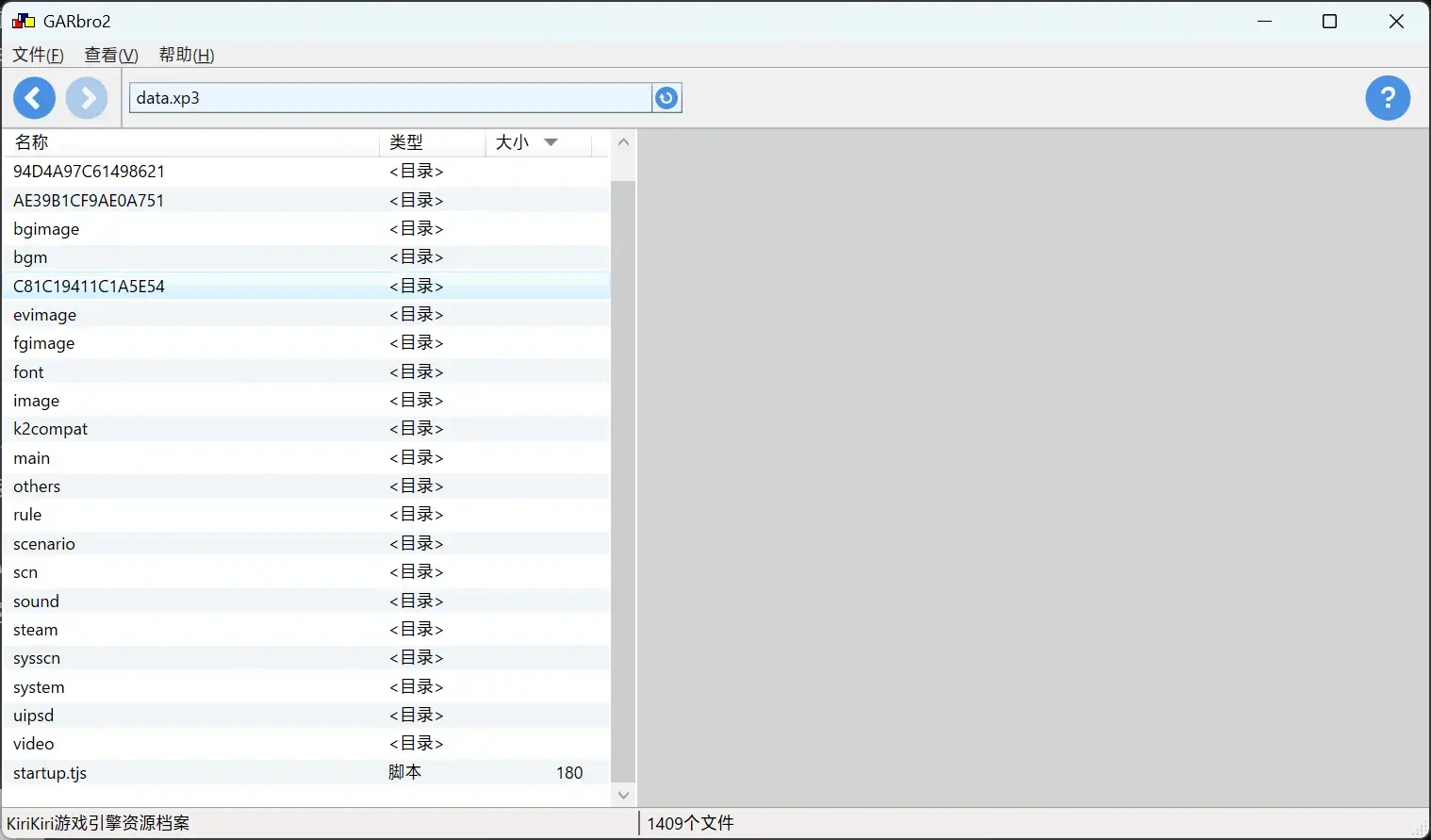 但似乎文件还在加密,是哪里出了问题吗?
但似乎文件还在加密,是哪里出了问题吗?

45 条回复